不知道大家有没有这种感觉,你与网页版的ChatGPT对话,和你调用API和GPT4o对话,返回的结果往往都是ChatGPT更好。明明它们背后使用的模型都是一样的,为什么结果却会不同呢?那就要聊聊我们今天的话题:“语言模型”和“智能体”。
关于“语言模型”,我之前也写过一系列的介绍文章,感兴趣的同学可以往前翻翻。
语言模型就像一个特别会“接话茬”的朋友,你说一半,它能帮你接下去;你提问,它会认真回答。
GPT4o就是“语言模型”。
那“智能体”是什么呢?你可以理解为“模型”的好伴侣,它有一定的“自我意识”,它的存在就是为了帮助模型更准确的回答问题。
ChatGPT就是一个“智能体”。
LLM的局限
在聊“智能体”之前,有必要再复习一点关于LLM的基础知识。
LLM是利用词嵌入和变换器架构来执行高级自然语言处理的神经网络。它们对人类语言有很好的理解,但不会在其知识库之外执行任何行动。
这里提到的“知识库”指的是LLM自己的固有知识库,也就是训练数据。这是不能变的,在“出厂”之前就已经决定了的。因此你不能指望模型能准确回答它的知识库之外的问题。
我在给模型提供外部知识库这篇文章中介绍了让模型使用外部文档作为知识库,这样就可以突破模型固有知识库的局限。此外再稍微扩展一下,当你的模型使用google搜索作为知识库的时候,它的知识库就是整个互联网。
一切看起来很完美,但是不知道你有没有发现其中最棘手的一个问题:不是所有查询都需要检索,有些问题大型语言模型(LLM)已经知道答案。如何分辨这些问题呢?
智能体
此时“智能体”就应该闪亮登场了。
在技术领域,AI智能体 是一个自主程序,可以执行任务、做出决策和与其他实体通信。通常,智能体会配备一套工具,它们可以决定在完成任务时使用。这一概念扩展了强化学习,智能体从一组定义的行动中选择以最大化交互环境中的奖励。
智能体需要做的事:
- 问题分类——将问题分类为事先规划的类别,以便后续使用工具
- 工具使用——使用各色工具为问题添加上下文
- 选择模型——优先使用专业性强的小语言模型进行第一轮回答
- 优化答案——将第一轮答案输入大语言模型进行总结,必要时再使用工具添加上下文
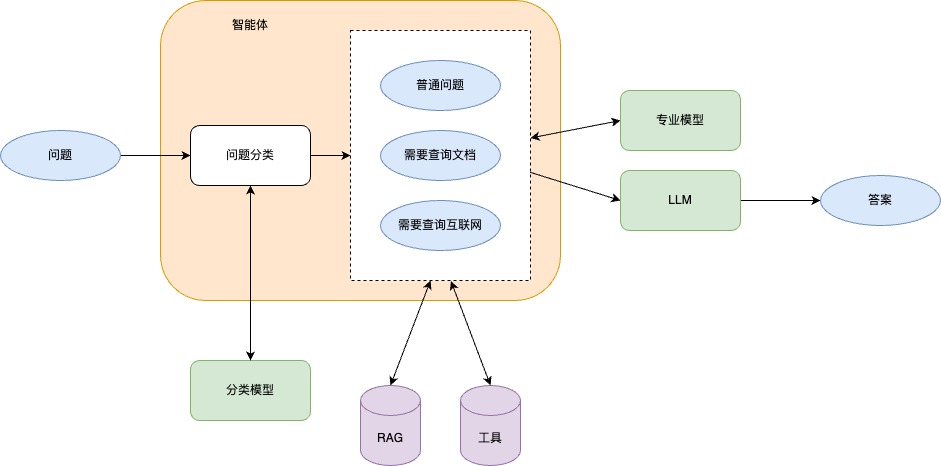
问题分类
一般在创建智能体前,需要事先规划一个问题类别表,并训练一个“分类模型“。这样做的目的是为了解决上面提到的那个棘手的问题:这个问题是否需要查询?(为了简化,我们只有一个工具,就是查询工具)
我们先建立一个这样的问题分类表:
| 类别 | 是否需要查询 |
|---|---|
| 翻译 | 否 |
| 摘要 | 否 |
| 扩写 | 否 |
| 润色 | 否 |
| 计划书 | 是 |
| 建议 | 是 |
再说一下“分类模型“,首先它应该能理解自然语言,其次它的工作就是文本分类。比如用户输入“将下列句子翻译成英语:……”,它能将问题归类为“翻译”;“我明天去xx,请给我穿衣建议。”,它能将问题归类为“建议”。
分类模型一般都是需要自己训练的,只有自己训练的才能满足自己的业务需求。
工具使用
如果智能体根据分类模型的结果判断出固有知识库无法回答用户的问题,智能体将尝试使用工具来获取外部知识库。我在让模型自主使用工具这篇文章中介绍了工具使用的原理。实际使用时可以用langchain等工具实现。此外,新版Ollama已经可以直接使用工具。
当智能体获取到外部知识库后,需要使用RAG技术将知识切片并向量化,最后使用算法将最相关的知识拼接成上下文。我在自己写一个RAG应用这篇文章中介绍了其原理。
选择模型
这一步是可选步骤。
一般情况下,大语言模型的知识往往多而不精,对于大部分情况是没问题的,但是如果遇到比较专业且深入的问题,往往不能给出令人满意的答案。
此时训练一个某领域非常专业的小模型也是必要的,一来更容易得到好的回答,另一方面小模型消耗的资源比较少,可以更好的对资源进行有效利用。
优化答案
这一步是可选步骤。
小模型的回答可能专业且准确,但文字组织方面不如大模型。最后可以让大模型进行总结和重写,生成更通顺(需要文案输出)或更紧凑(需要节省成本)的答案。
总结
最后再来回顾一下一开始我们提到的问题:为什么你与网页版的ChatGPT对话,和你调用API和GPT4o对话,返回的结果往往都是ChatGPT更好?相信通过这篇文章,你有答案了吧。