在之前的文章中,我们介绍过使用RAG技术给大语言模型添加外部知识库。今天我们就来详细了解下RAG,并且不用任何框架,自己动手做一个RAG应用,从原理上理解其运行逻辑。
什么是RAG
RAG is an AI framework for retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process. —— from IBM Research.
RAG 是一个人工智能框架,用于从外部知识库中检索事实,使大型语言模型(LLM)基于最准确的最新信息,并让用户深入了解 LLM 的生成过程。
大语言模型训练完后,其内部知识库就已经确定了,所以它无法回答你超过其知识库内容的问题。除非你有能力对其进行微调,否则最简单的方法就是使用RAG检索外部知识库。
有人可能会认为,RAG是不是就是让模型在回答问题前先去指定的外部知识库检索一下知识,然后再回答?这里只对了一半,模型没有那么智能,它不能主动去“检索”知识库,而是需要我们把检索到的知识“喂”给模型,让它结合“知识”和“问题”,做出合理解答。
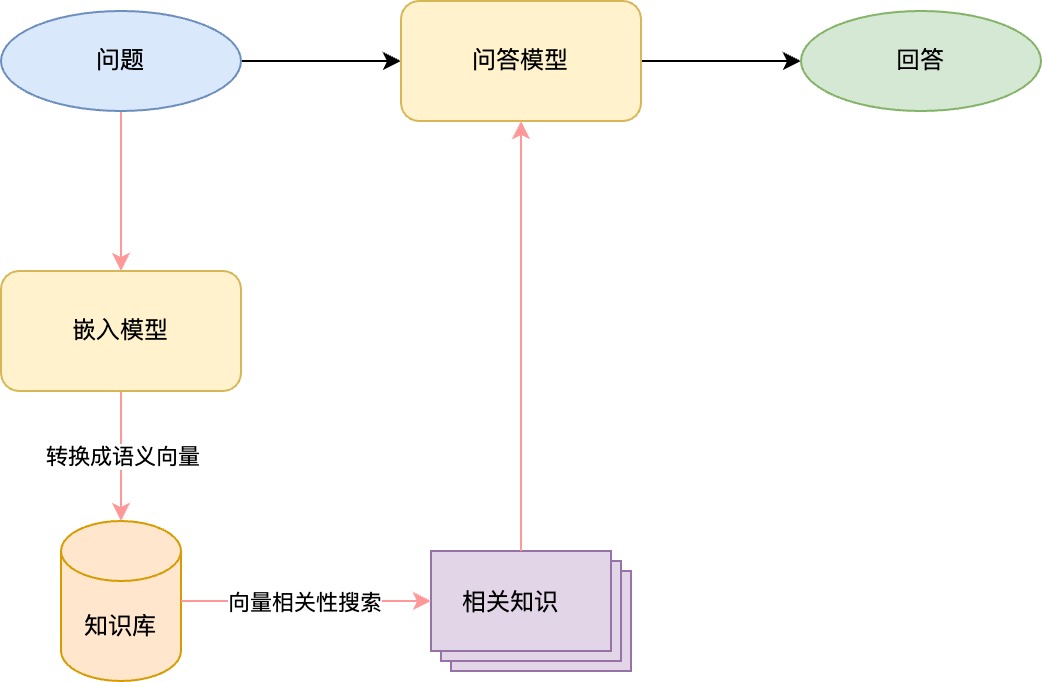
上图展示了没有使用RAG和使用RAG后的两种工作流程。黑色箭头就是没有使用RAG的工作流程。那这里为什么要引入一个嵌入模型呢?别急,我们这里还需要再了解一些基础知识。
非结构化数据和向量搜索
什么是结构化数据?二维表格(行和列)是最常见的结构化数据形式。它具有非常良好的关键字查询功能,只要找到对应的单元格,就能定位到行和列。它就好比传统的SQL搜索,能进行精确查询和模糊查询,但不能进行相关性查询。
那什么是非结构化数据呢?答案是任何文本、图片、音频、视频文件等。将这些数据进行多维展开,实现空间上的向量化。任何两个数据向量化后,如果在空间上具有相似性,就可以认为这两个数据相关联。比如一张小孩一个人荡秋千的照片和单词“孤独”可能在空间中非常接近,这样一来,使用关键词“孤独”进行向量搜索,能把这张图片查询出来。这在传统数据库加结构化数据中是很难做到的。
现在你知道什么是向量搜索了吧?向量搜索是一种基于向量空间模型的搜索技术。向量搜索的目标是在向量空间中找到与查询向量最相似的向量,即与查询向量距离最近的文档向量。
向量搜索的最常见算法是“余弦相似度”,这个我们不做展开。
到了这里,你一定了解了为什么RAG中要引入一个嵌入模型的原因了吧。
构建知识库
知识库可以是任意非结构化数据组成的,我们这里用一个txt文本做示例。
文本分割
首先第一步需要将文本分割,这一步很好理解,就是将大文本分割成多个小块。不管是pdf还是word,分割成小块后就可以用于检索了。因此这一步很重要,分割后的文本质量影响检索的准确性。这里给一个通用的算法,根据指定的文本长度进行分割。
| |
你可以将分割后的文本保存至磁盘或任何你喜欢的数据库。
文本嵌入
接下来将分割后的文本嵌入成向量。我这里使用的模型是m3e-base,它对中文支持良好。
| |
构建索引
不用现成向量数据库是为了让大家更深的理解RAG的整个原理。
对向量进行索引以提高搜索效率,使用ANN算法构建索引。
| |
你可以将生成的索引保存至磁盘或任何你喜欢的数据库。
至此知识库构建完毕。
实现RAG
当知识库就位后,接下来就是提问了。
问题嵌入
非常简单的一步,将用户的提问转换成向量。
| |
语义搜索
将嵌入后的数据在索引中搜索,根据语义查找相关度最高的几(top_k)条数据。
| |
semantic_scores语义得分,是一个语义相似度得分数组,类似于[333.7204, 320.6714, 303.9030, 301.7744],得分越高,相似度越高。
semantic_indices与语义得分相对应,对应的是上面chunks的下标,类似于[1, 3, 2, 0]。
混合搜索
本步骤可选。
语义搜索可以找到相似文本。但为了提高准确度,往往需要结合一种其它的相似度算法来重新计算相似度得分。接下来我们使用BM25算法来举例。注意,下面这段代码,需要加到“构建知识库”的步骤中。
| |
稍微解释一下,这段代码的核心步骤是预处理文本并构建BM25索引:
- 下载
nltk库中的停用词数据集,停用词是指在文本处理中需要过滤掉的一些高频但无意义的词语,如“的”、“是”、“在”等。 - 用
jieba分词对中文进行分词,并过滤掉停用词,使得剩下的词更具备实际意义。 chunks是上文“文本分割”后的小段文本,对每段文本进行索引构建。
接下来结合BM25得分和语义得分来重新计算最终得分,选出排名靠前的文档。
| |
- 用
jieba分词对问题进行分词,并过滤掉停用词。 - 计算
BM25搜索得分。 - 使用
semantic_indices对BM25得分进行重排序或筛选,得到与语义得分相关的BM25得分bm25_scores_rescored。 - 标准化得分:将语义得分和
BM25得分标准化到[0, 1]范围内。 - 计算调和平均得分:将标准化后的语义得分和BM25得分结合起来,计算它们的调和平均数作为最终的组合得分
combined_scores。 - 排序和选取前
K个文档
最终的result是类似于这样的结果:[(3, 0.7433483727390585), (2, 0.11336547324137035)]。这意味着查询到两条数据,下标分别是3和2,得分分别是0.7433483727390585和0.11336547324137035。
构建提示词
这一步也很简单,假设用户的问题是question1,查询到的结果是result1和result2。那么构建的提示词如下(仅供参考):
| |
这里要注意的是不同模型的上下文长度,不要超过它的最大长度。
参考
https://github.com/Rman410/hybrid-search/blob/main/hybrid-search.py