RLE算法介绍
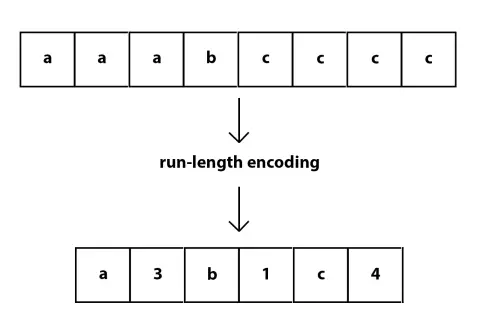
RLE(Run Length Encoding,行程长度编码)算法,是把文件内容用“重复次数x数据”的形式来表示的压缩方法。比如:有AAAAAABBCDDEEEEEF这样一段数据,在字符后面加上重复出现次数,就可以用6A2B1C2D5E1F来表示。可以看到原始数据是17字节,编码后是12字节,因此压缩是成功的。
让我们再看一串数据:ABCDE,如果按照上面的算法,编码后为1A1B1C1D1E,原始数据是5字节,编码后是10字节,毫无疑问这种压缩方式是失败的。
为什么第二种字符串压缩会失败呢?细心的朋友一定看出来是因为它的字符重复出现的次数很少,因此使用“重复次数x数据”反而增加了数据长度。那有没有办法解决这个“缺陷”呢?答案是有的。我们接下来介绍在PS2游戏机中,是如何使用RLE算法来压缩图片的。
RLE算法在PS2中的应用
在PS2中,图片文件的前4个字节指示了压缩后文件的大小。接下来的数据按照rle_code + 数据块的格式重复排列。需要注意的是,在PS2这里,rle_code和数据块中的每个数据,都是2字节,这点是与其它传统的RLE算法普遍为1字节最大的不同。
rle_code的最高位是标识位,如果这一位是1,则表示后面紧跟着的数据块是“非重复数据”,类似于上面的ABCDE。此时将0x8000减去rle_code的后7位,得到的是数据块的长度。此时只需取出后面紧跟的该长度的数据块即可。
如果标识位为0,则表示后面紧跟着的数据块是“重复数据”,类似于AAAAA,此时rle_code就是重复次数,只要取出后面紧跟着的一个数据块,重复rle_code次即可。

伪代码如下:
| |
总结
如果在一个文件中,能连续遇到大量重复的数据,RLE算法可以提供很好的压缩效果。但对于出现连续的“非重复数据”,需要使用改良过的算法进行优化。PS2使用的是众多改良算法的一种,比较简单,也很方便初学者对该算法的学习。