With the rise of ChatGPT, LLMs (Large Language Models) have become a hot topic in the field of artificial intelligence and natural language processing. In this article, I will walk you through the process of running a large language model on your own personal computer.
Pros and Cons
There are many advantages to running a large language model locally:
- Privacy protection
- No expensive costs
- Ignore network problems
- Try out various open source models
I think the first two advantages are enough for everyone to try. Everyone has some private data that they don’t want to send to third parties. If you can use AI to process private data locally or even offline, isn’t that perfect? In addition, locally, no matter how much data you run, you don’t need to pay for API and token fees. Are you excited?
Of course, there are also disadvantages:
- Not for beginners
- The “intelligence” of open source models is worrying compared to commercial models
- Personal computer configuration is weak, it is impossible to run the full power of the model
But fortunately, there are many tools in the open source world, and “intelligence” can be slowly “trained” through tools. I believe that as long as you are willing to try, you will be able to train a model that you are satisfied with.
Tool Selection
I will mainly introduce 3 tools for running LLMs locally:
- LMStudio: https://lmstudio.ai/
- llamafile: https://github.com/Mozilla-Ocho/llamafile
- Ollama: https://ollama.com/
I have used all three of these tools, and the usage methods are very similar. The installation is also very simple. If you are interested, you can try them all. But in terms of stability and convenience, I would recommend Ollama.
Running Ollama
Installation
The installation of Ollama can be downloaded from the official website. Just download the corresponding installation package according to your operating system. Although the installation package is provided, there is no GUI interface. All operations need to be performed by command line.
Pull Model
The first step after installation is to pull a model. The command is very similar to the docker command:
| |
Speaking of models, it’s very interesting. First of all, you can go to the official website: https://ollama.com/library to find and download the model you like. At present, major companies have more or less open sourced their own large language models. You should have heard of many of them in various news reports. But if you are a beginner, I recommend a few models here:
- llama2 (a large language model released by Meta, Facebook’s parent company)
- mistral (a large language model released by a French AI company)
- qwen (a large language model released by Alibaba, you have heard of Tongyi Qianwen, right?)
- llava (a large language model that can perform image recognition)
Why is it interesting? Because these models open sourced by these big companies are not their strongest models, in other words, they are all reserved. Because the strongest models are all reserved for their own commercial use. This means that these models are more or less “retarded” when they are first obtained, and they cannot understand your intentions and give you good answers at first. This is also the reason why I said later that it needs to be “trained”.
Model Parameters
The model pulled by the command ollama pull llama2 is the default parameter. If you have requirements for the parameters, you can click the Tags tag of the model and choose the appropriate parameters yourself.
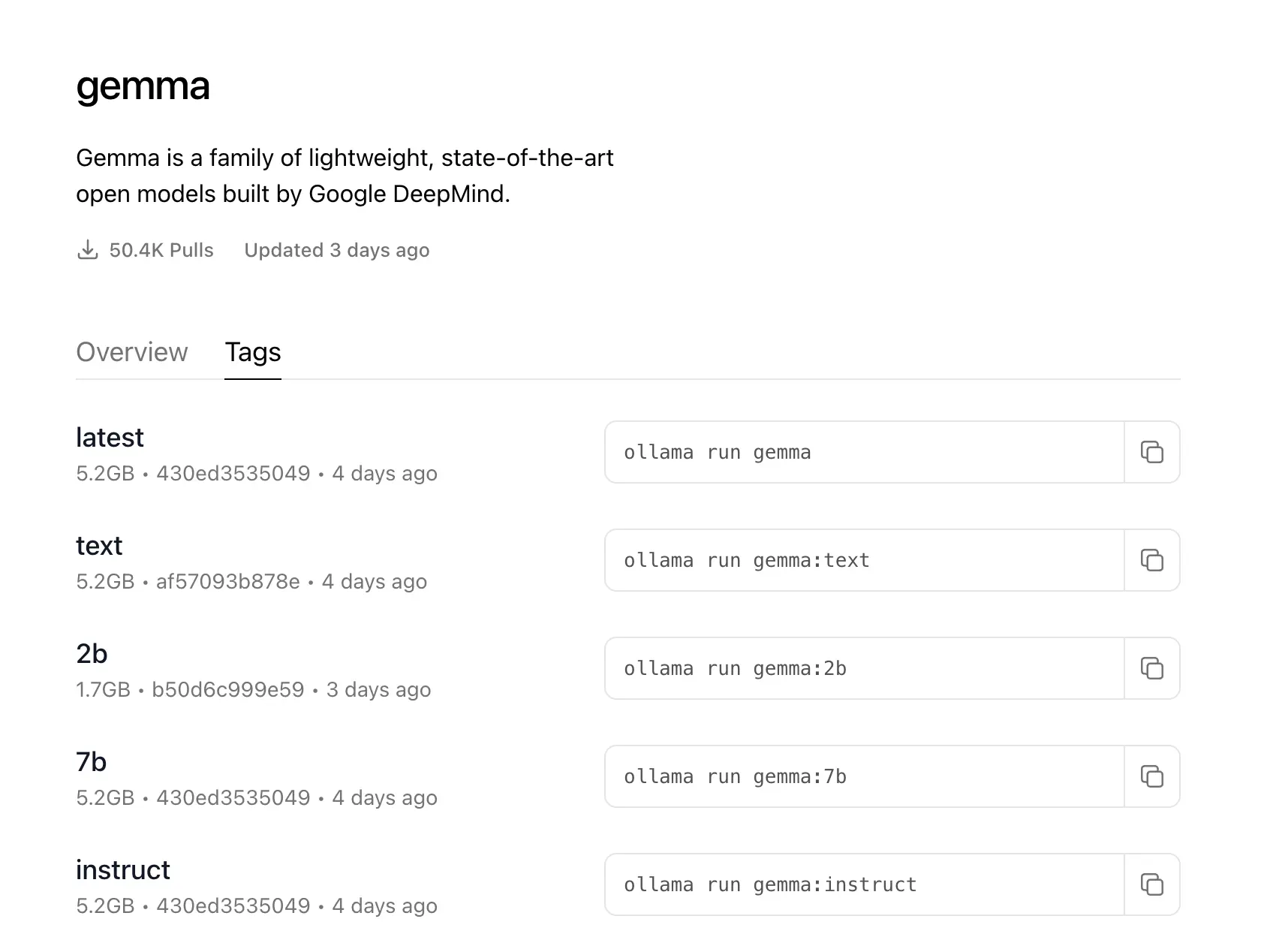
Here is a brief explanation of the main parameters:
2b, 7b, 13b- The number of parameters of the model during training, b stands for 100 million. The larger the result, the more accurate, the more resources it will occupy, and the longer it will take to generate the result. 7B requires at least 8GB of memory, and 13B requires at least 16GB of memory.instruct, chat, text- instruct, chat is more suitable for chatting, text is more suitable for content generation (see [Ollama API](#Ollama Api)).
q2, q4, q8- Model quantization value, the larger the more accurate, but the more memory it occupies, The same time to generate the result will also be longer. These parameters can be selected according to your computer configuration. MyM1chip MacBook generally chooses7b_q8.
Running
After pulling the model, you can use the ollama list command to view all installed models. Then you can run Ollama.
There are two ways to run Ollama. One is the command line mode, enter ollama serve to start the service. The other is to click on the application shortcut to run. This method will display an Ollama icon in the status bar. No matter which method is used, after starting the service, it will occupy port 11434.
At this time, you can connect Ollama to any ChatGPT client that supports modifying the API address (because the latest version of Ollama has adapted to OpenAI's API). In addition, some apps can also be directly configured if they are compatible with the Llama API interface:
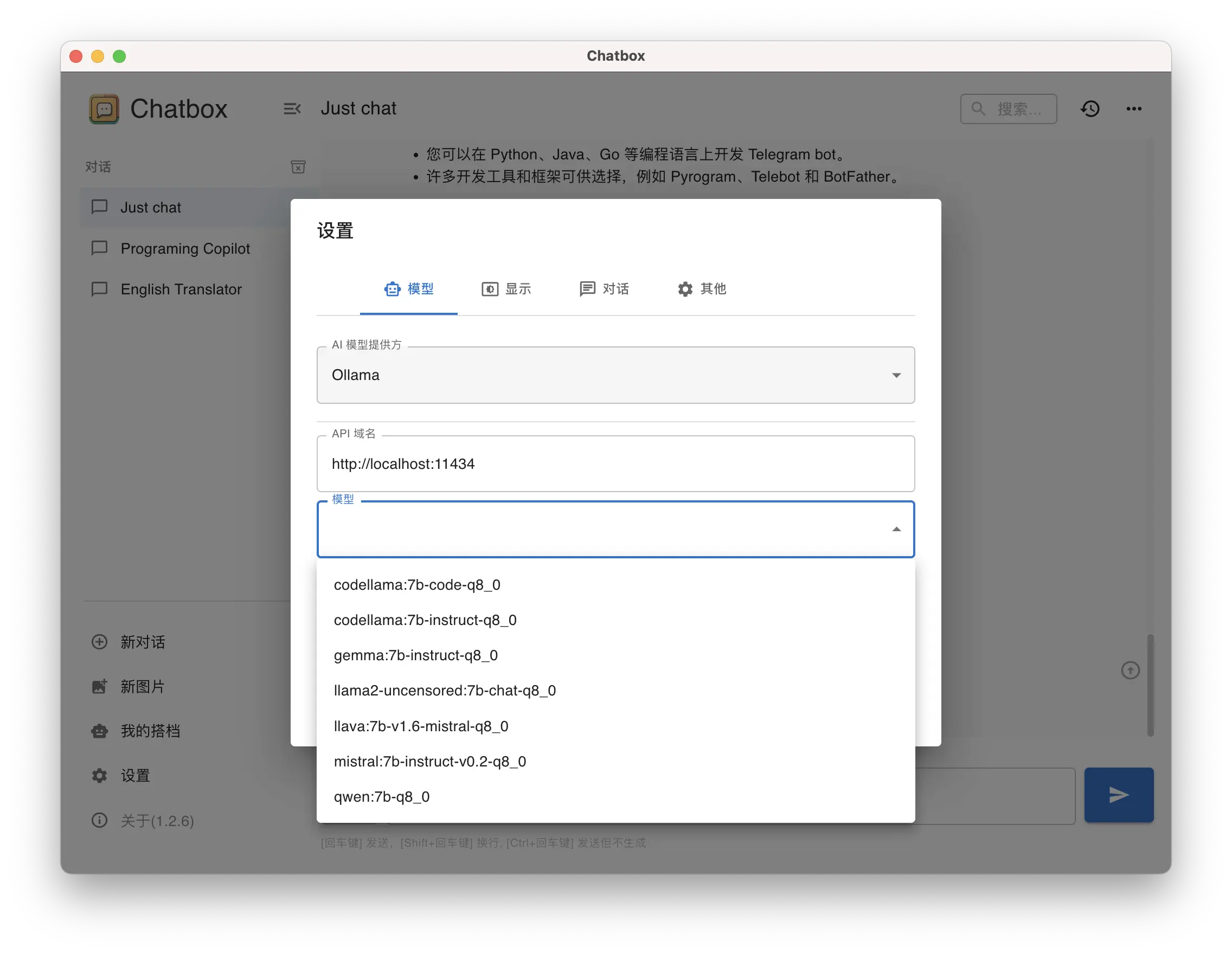
Ollama API
The API documentation is here: https://github.com/ollama/ollama/blob/main/docs/api.md, I will only introduce two here.
| |
The first is content generation, and the second is chatting with the model. The two APIs require different parameters. You can refer to the documentation for details. Here, I will mainly talk about the difference between these two interfaces.
The generate interface emphasizes generation, so you need to provide all the prompts to it at once, so that you can generate a more ideal result.
The chat interface emphasizes chatting, which is also the scenario used by most ChatGPT clients. It chats with the model back and forth, and each chat will include all the previous contexts. Therefore, you can gradually give it prompts after chatting with the model a few times.
Model Testing
Next, let’s write a script to test how different models perform in content generation.
First, install the corresponding package: pip install ollama.
Then write a Python script. This script defines several simple roles:
| |
This script is very simple, you can run it on your own computer. Through my observation, the conclusion is that most language models do not support Chinese well. Chinese-to-English translation is acceptable, but English-to-Chinese and Japanese-to-Chinese translation are often nonsensical. “Tongyi Qianwen” performs the best in terms of Chinese support. However, the answers from “Tongyi Qianwen” always seem to go off on strange tangents, which can be disappointing.
Here are the answers from 3 models for the prompt “The Four Great Classical Novels of China”:
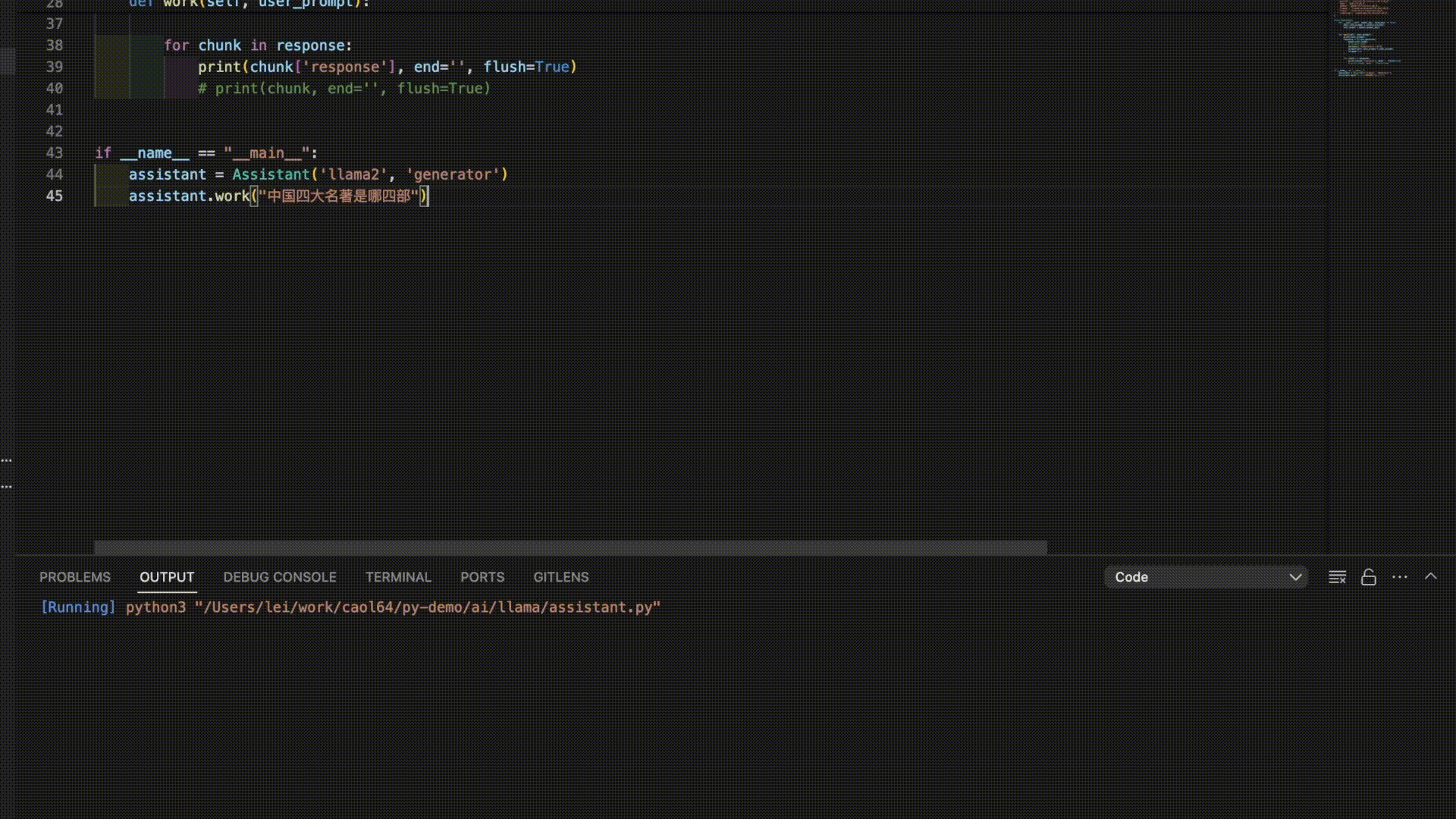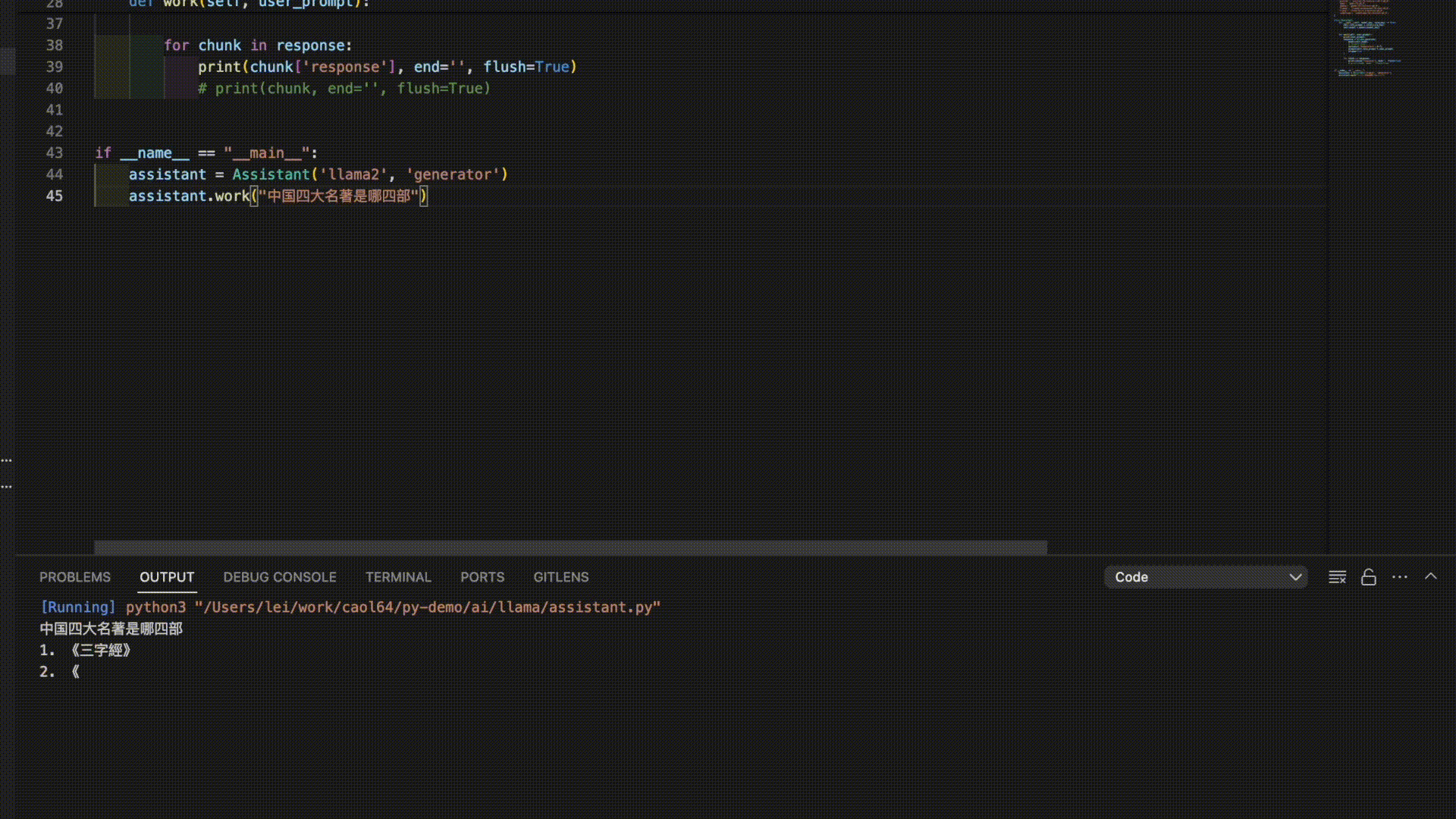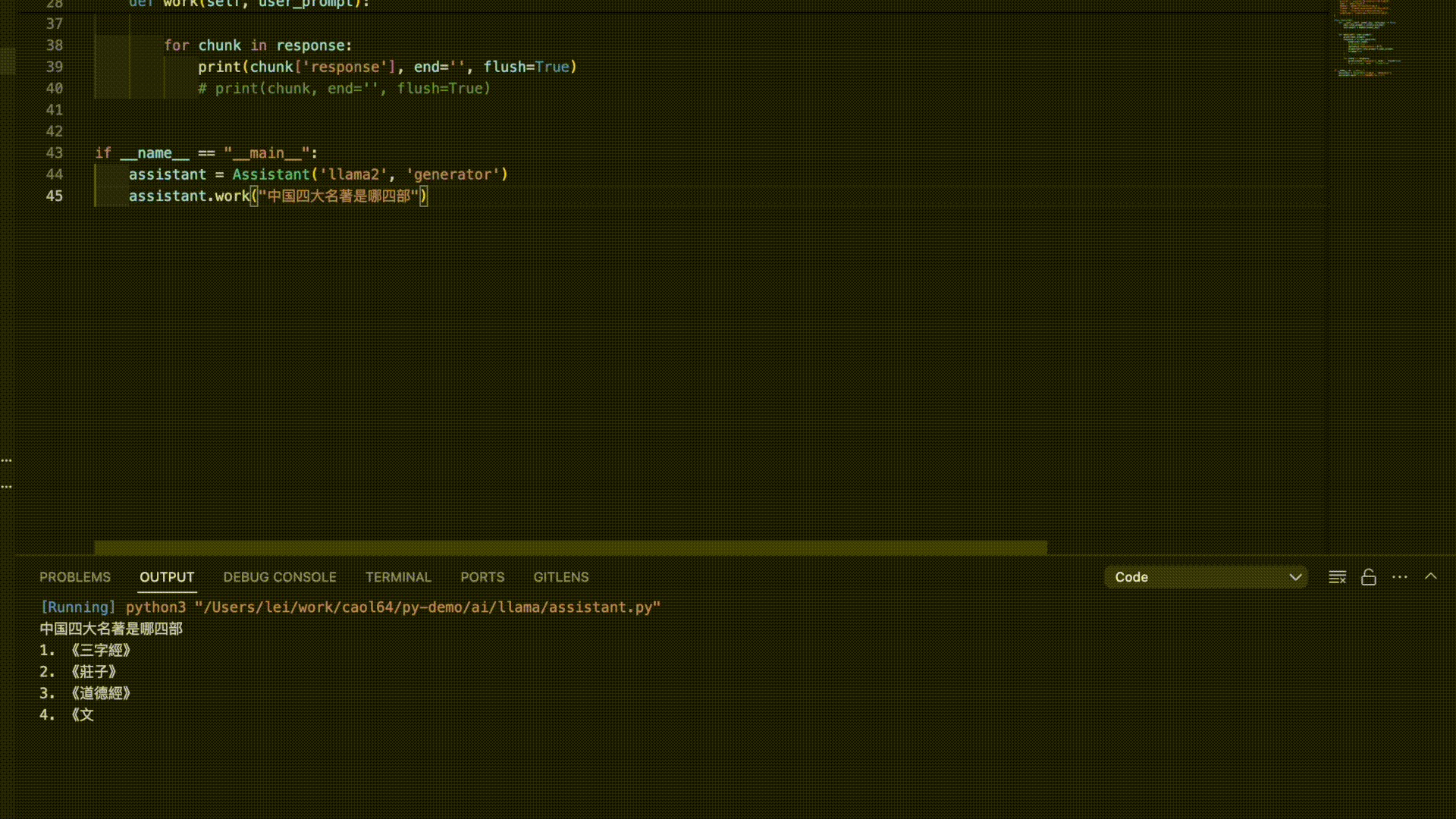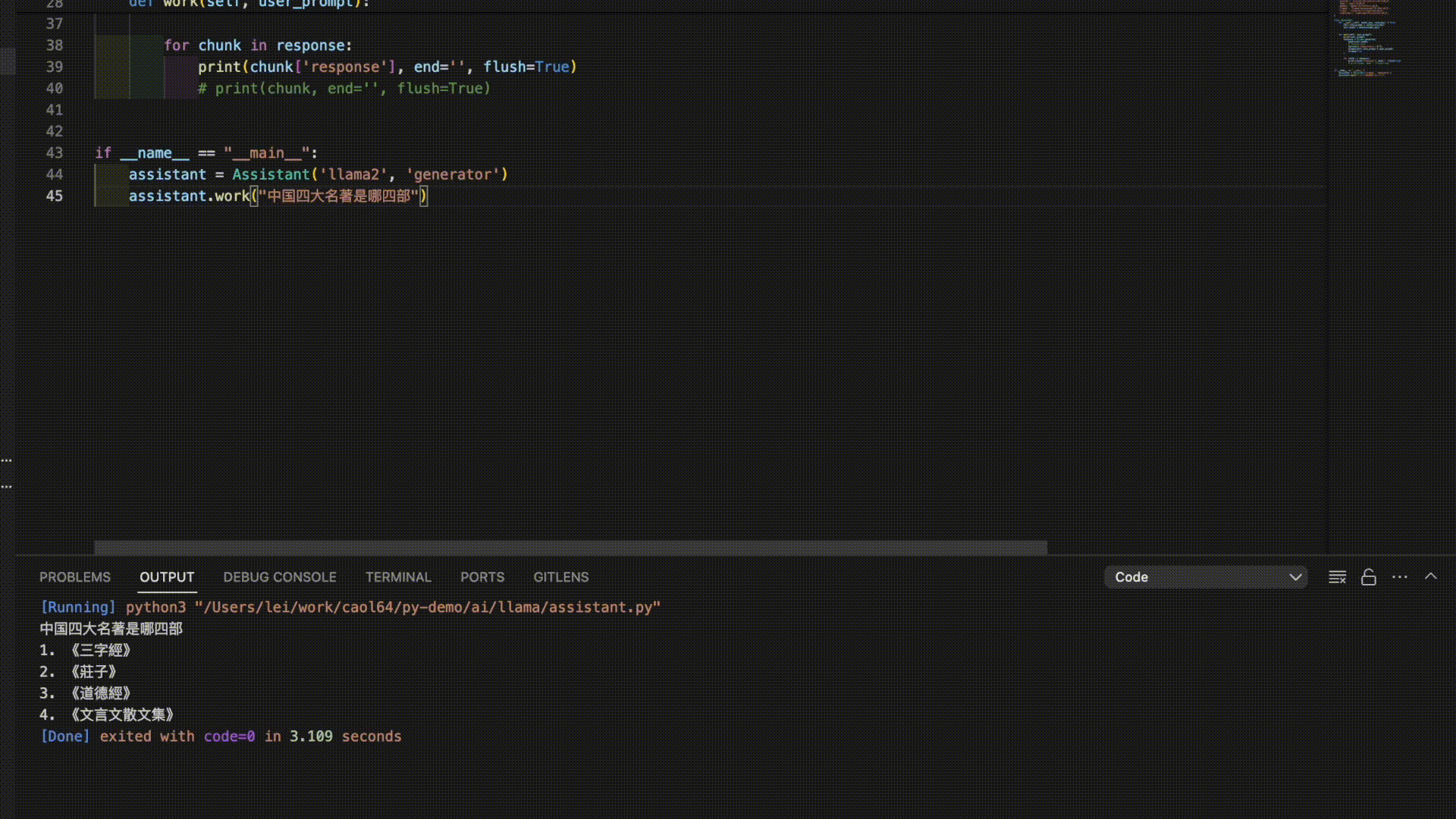
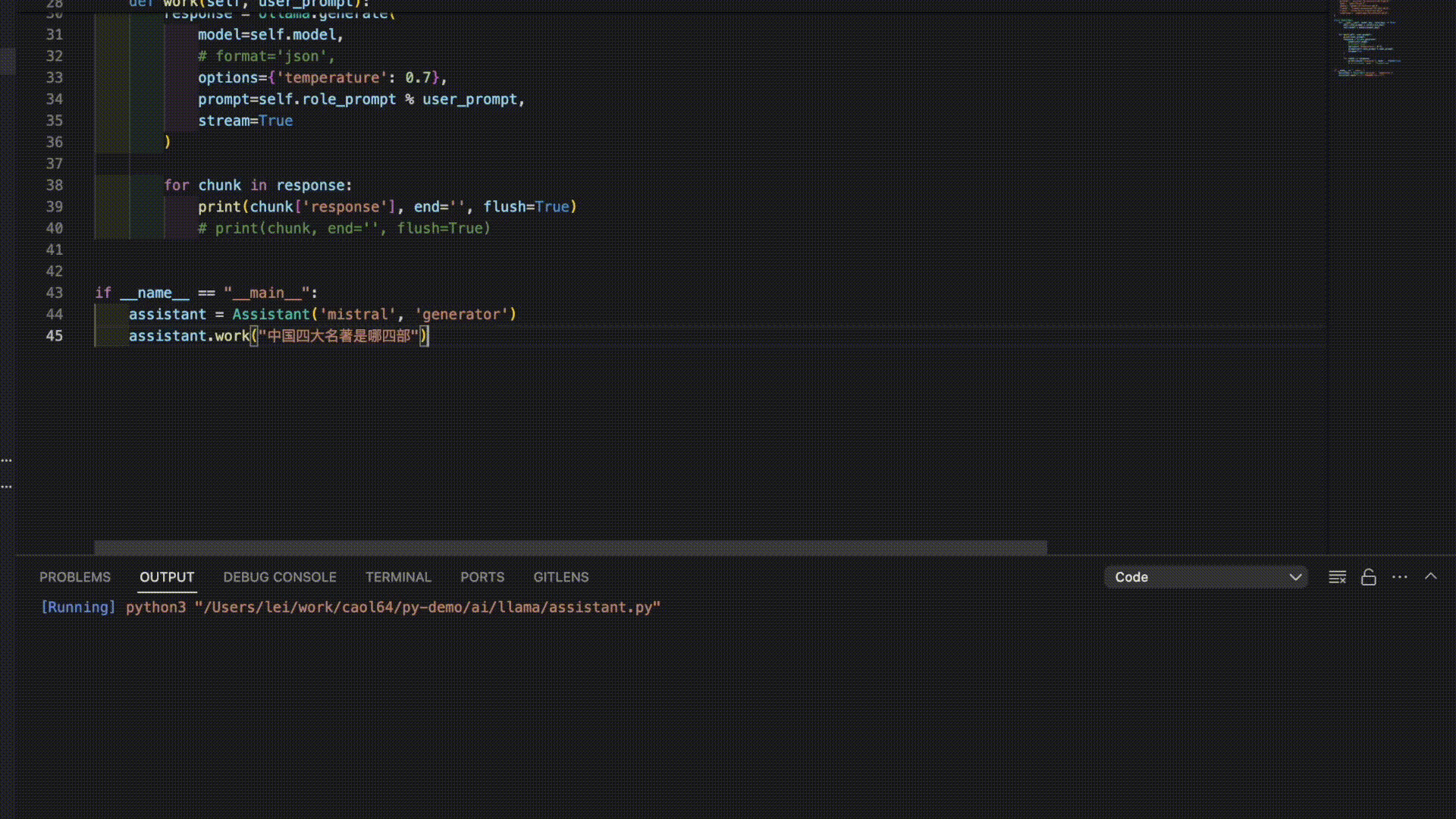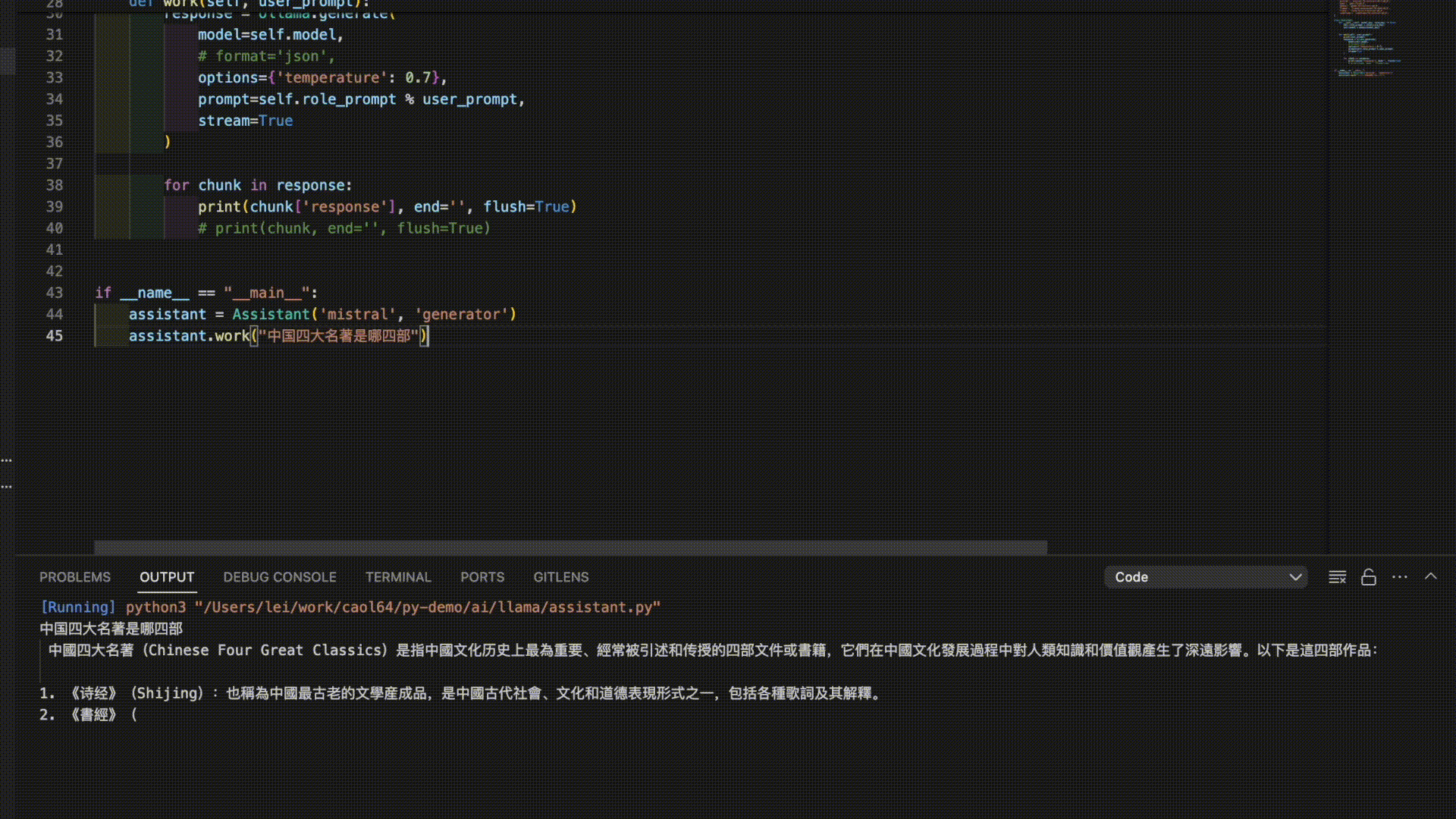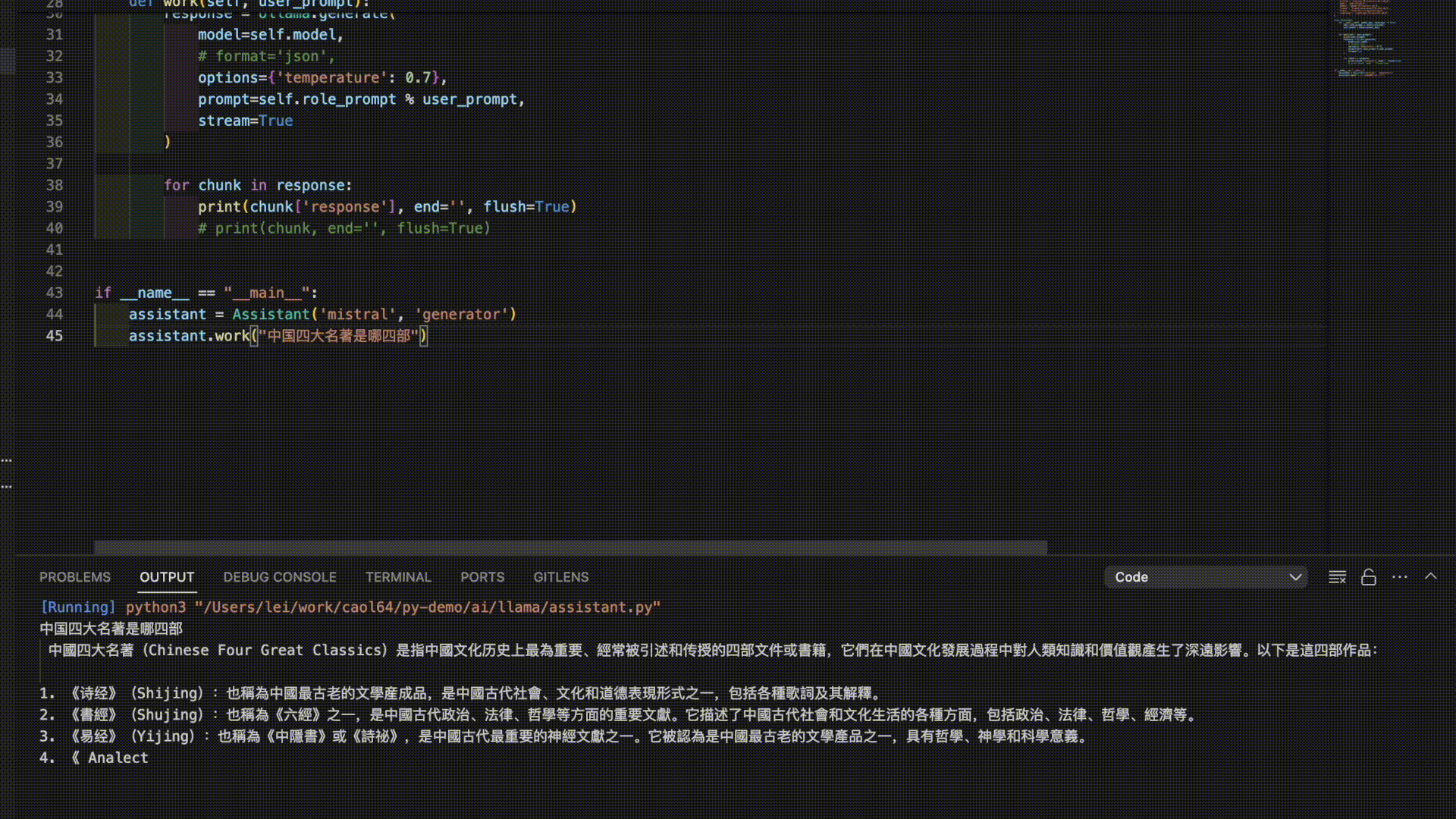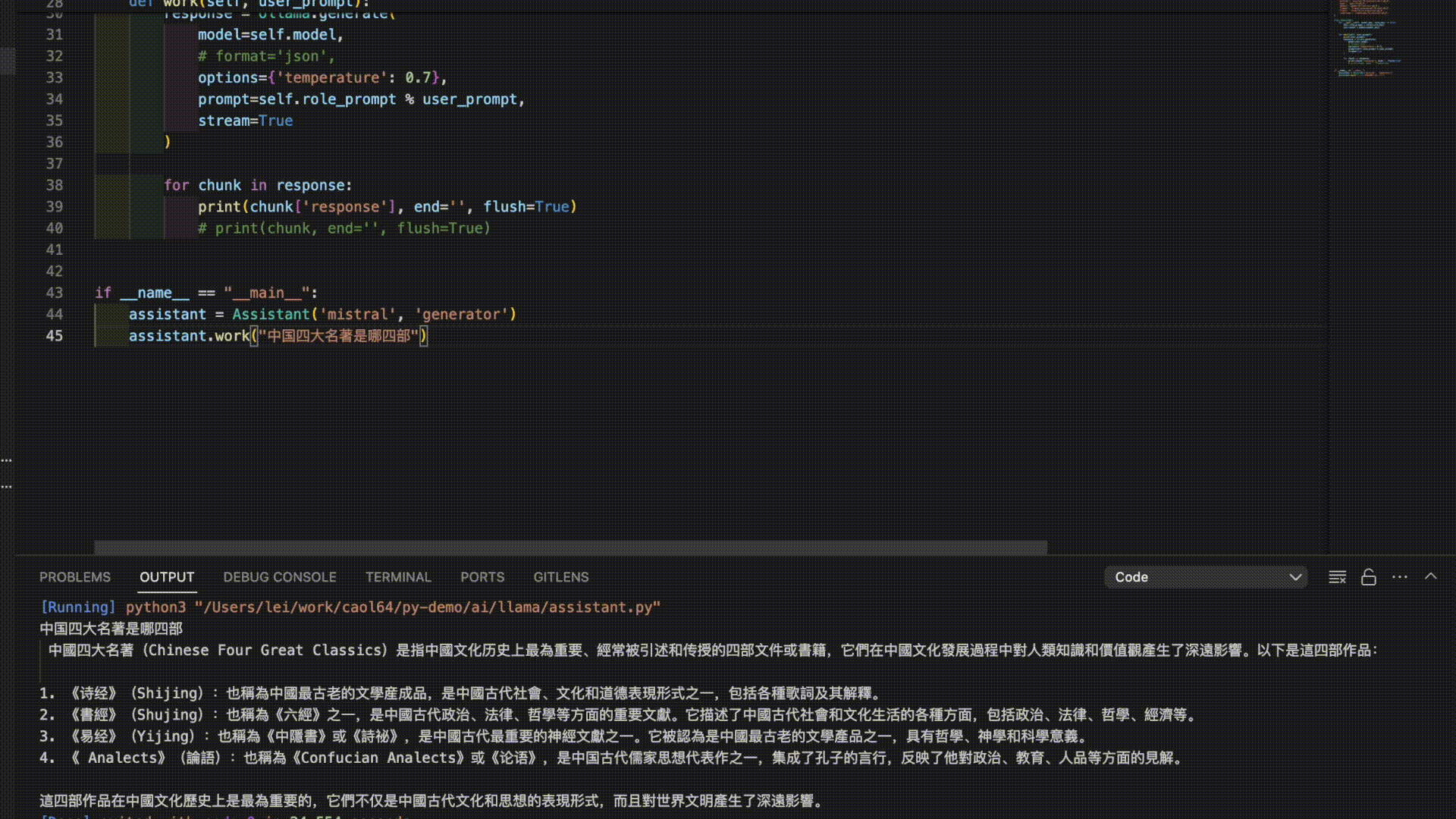
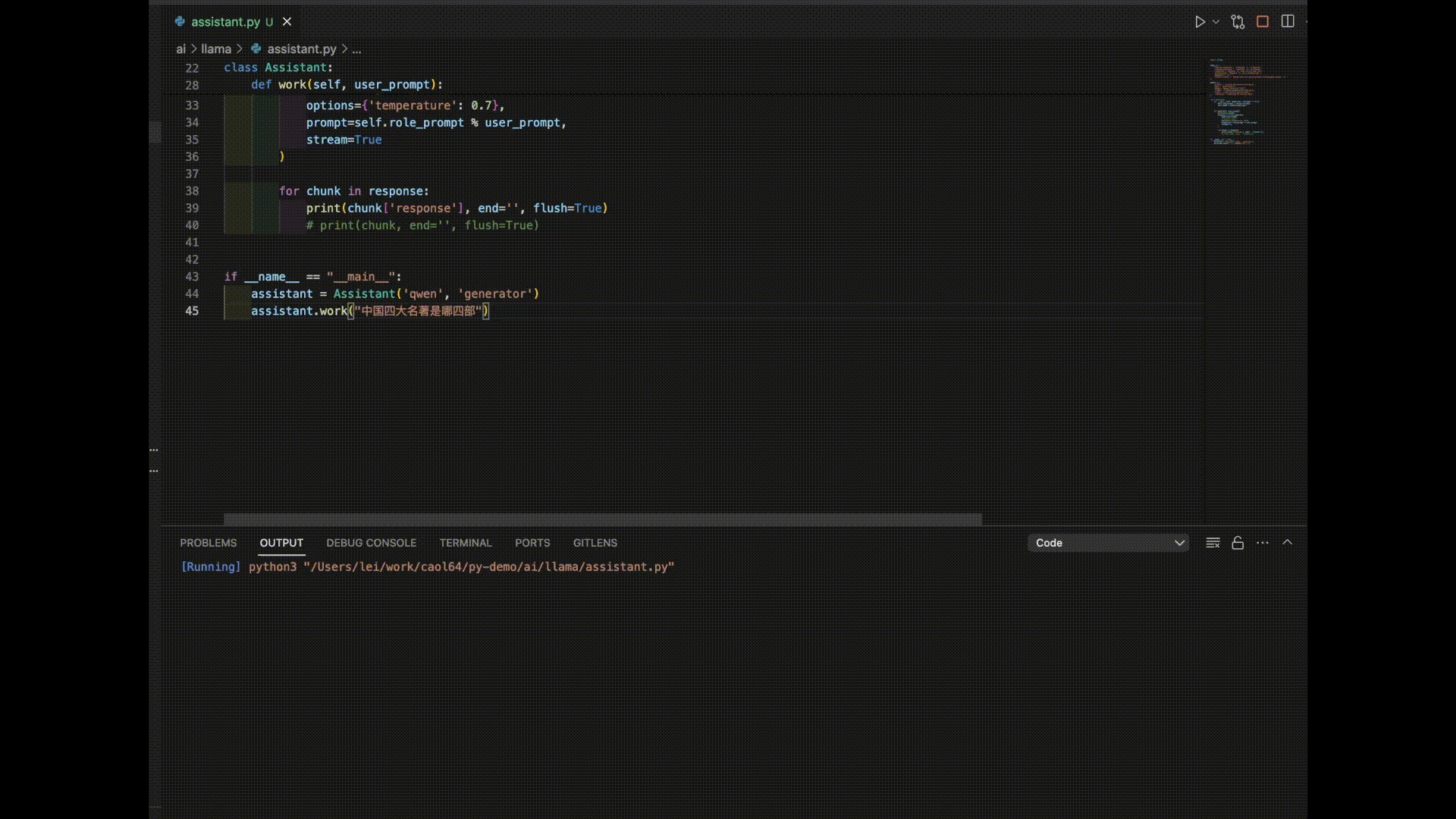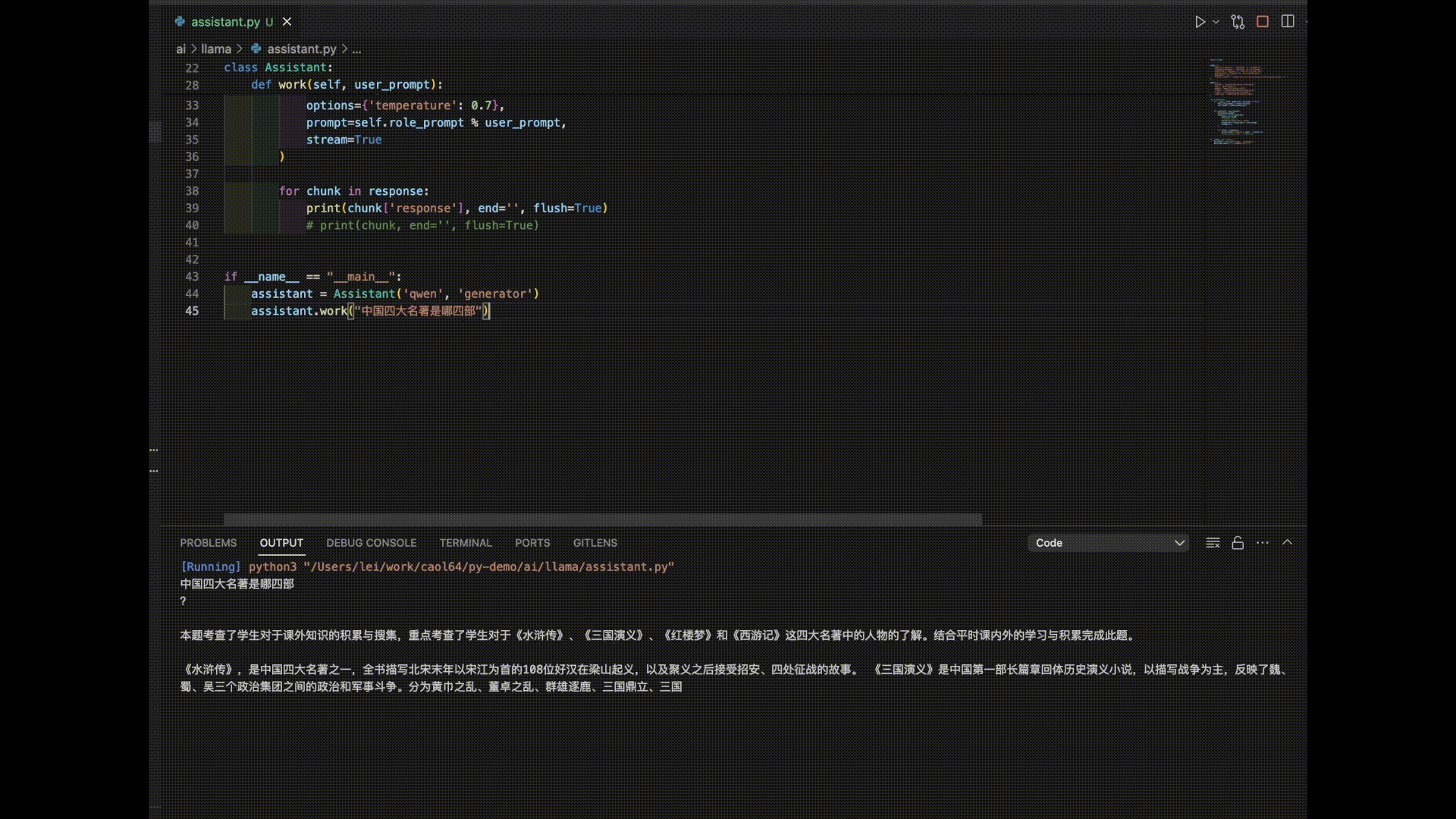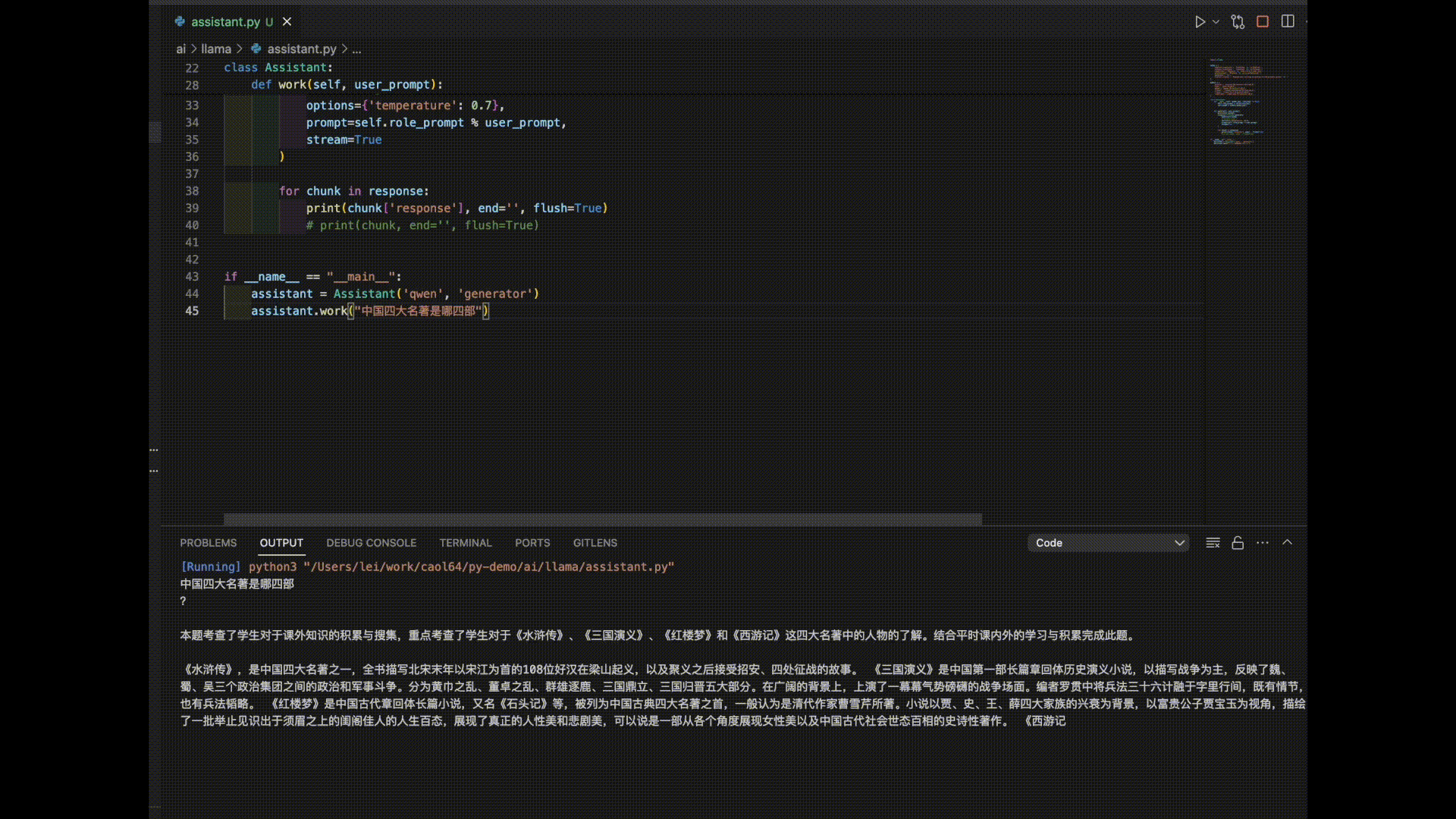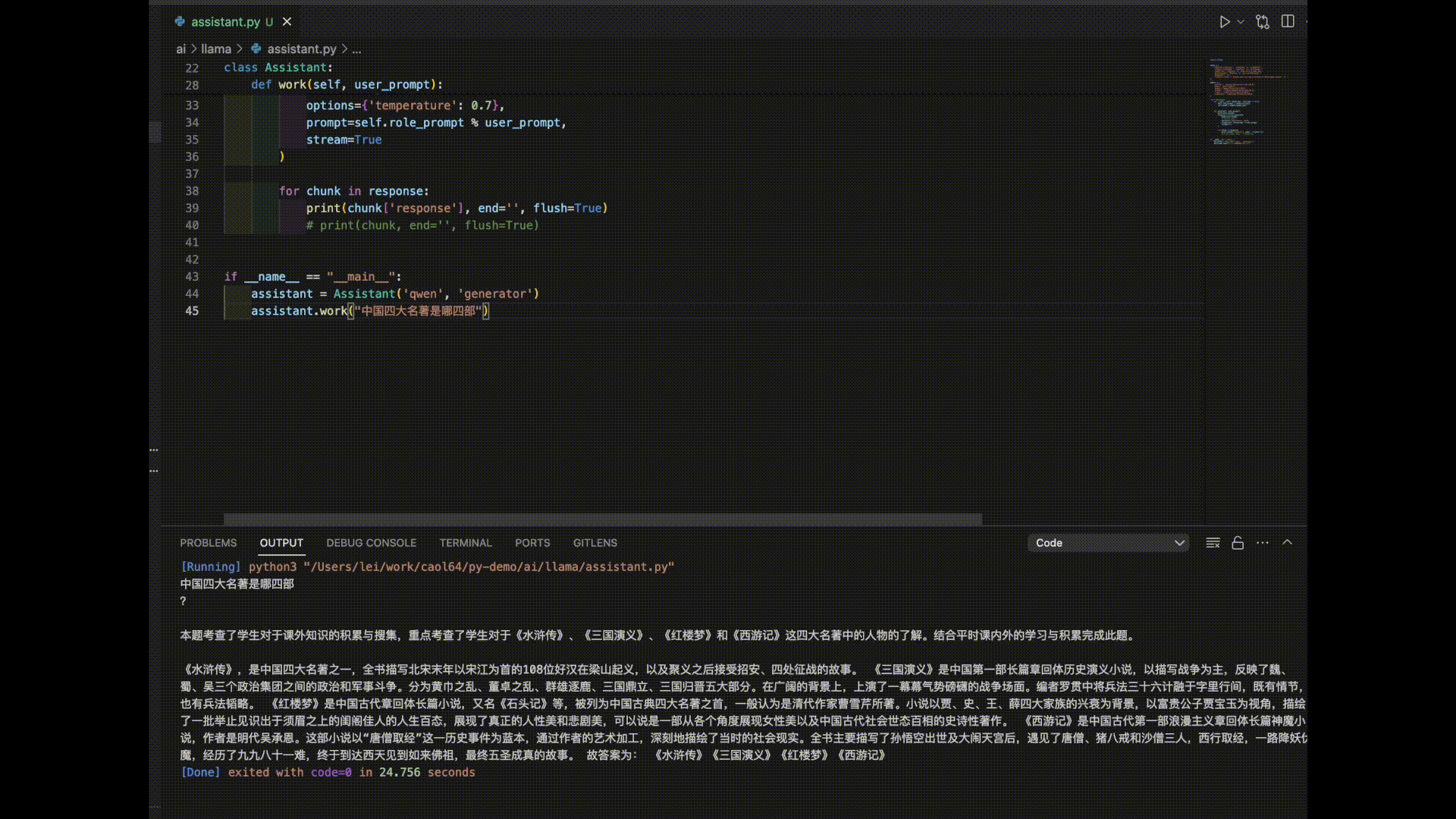
As you can see, it seems like it’s time to further train these models!