Introduction to RLE Algorithm
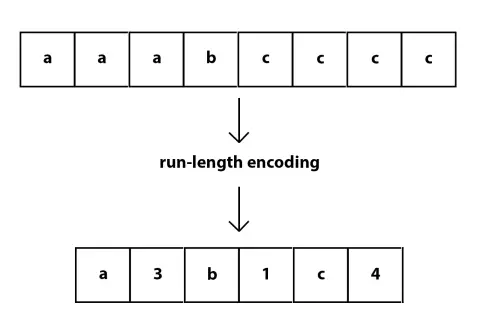
The RLE (Run Length Encoding) algorithm is a compression method that represents file content in the form of “number of repetitions x data.” For example: given the data AAAAAABBCDDEEEEEF, by appending the number of consecutive occurrences after each character, it can be represented as 6A2B1C2D5E1F. It can be observed that the original data is 17 bytes, while the encoded data is 12 bytes, thus achieving successful compression.
Let’s consider another string of data: ABCDE. If we apply the above algorithm, the encoded form would be 1A1B1C1D1E. The original data is 5 bytes, but the encoded form is 10 bytes. Undoubtedly, this compression method fails.
Why does the compression fail for the second string? Astute readers will notice that it’s because the characters in it have very few consecutive repetitions. Therefore, using the “number of repetitions x data” approach actually increases the data length. Is there a way to address this “defect”? The answer is affirmative. Next, we will explore how the RLE algorithm is used to compress images in the PS2 game console.
Application of RLE Algorithm in PS2
In the PS2, the first 4 bytes of an image file indicate the size of the compressed file. The subsequent data is arranged in the format of rle_code + data block repeated. It’s noteworthy that in PS2, both the rle_code and the data block consist of 2 bytes each, which is a notable difference from other traditional RLE algorithms where typically only 1 byte is used.
The most significant bit of the rle_code serves as a flag. If this bit is 1, it indicates that the following data block is “non-repeated data,” similar to the example ABCDE mentioned earlier. In this case, subtracting the last 7 bits of rle_code from 0x8000 yields the length of the data block. Then, it’s sufficient to extract the following data block of that length.
If the flag bit is 0, it indicates that the following data block is “repeated data,” similar to AAAAA. In this case, rle_code represents the number of repetitions, and it suffices to extract a single data block following it, repeating it rle_code times.

The pseudo code is as follows:
| |
Conclusion
If a file contains a large amount of consecutive repeated data, the RLE algorithm can achieve good compression results. However, for consecutive occurrences of “non-repeated data,” it requires the use of optimized algorithms. PS2 employs one of many improved algorithms, which is relatively simple and convenient for beginners to learn about this algorithm.